学AI大模型必看!手把手带你从零微调大模型!

今天分享一篇技术文章,你可能听说过很多大模型的知识,但却从未亲自使用或微调过大模型。
今天这篇文章,就手把手带你从零微调一个大模型。
大模型微调本身是一件非常复杂且技术难度很高的任务,因此本篇文章仅从零开始,手把手带你走一遍微调大模型的过程,并不会涉及过多技术细节。
希望通过本文,你可以了解微调大模型的流程。
1,微调简介
微调大模型需要非常高的电脑配置,比如GPU环境,相当于你在已经预训练好的基础上再对大模型进行一次小的训练。
但是不用担心,本篇文章会使用阿里魔塔社区提供的集成环境来进行,无需使用你自己的电脑配置环境。
你只需要有浏览器就可以完成。
本次微调的大模型是零一万物的 Yi 开源大语言模型,当然微调其他大模型的过程和原理也有差不多。
这里说明一下,阿里魔塔社区对于新用户提供了几十小时的免费GPU资源进行使用,正好可以来薅一波羊毛,学习一下大模型的微调。
话不多说,直接开始。
2. 账号和环境准备
首先你需要注册和登录魔搭的账号:modelscope.cn/home
注册完成后,登录这个模型网址:
www.modelscope.cn/models/01ai…**.**
然后按照下面的箭头操作。
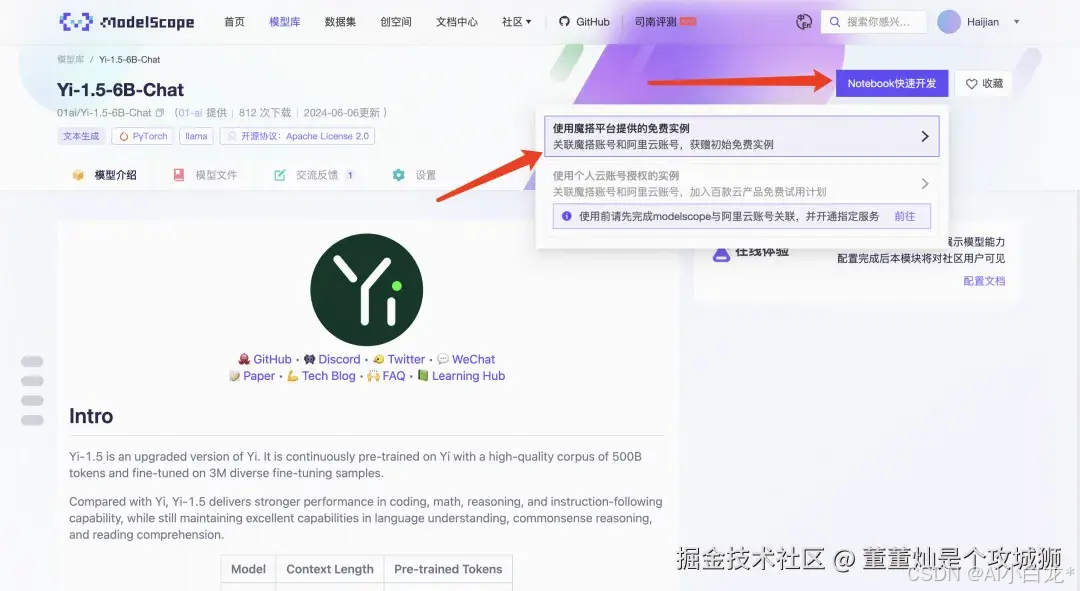
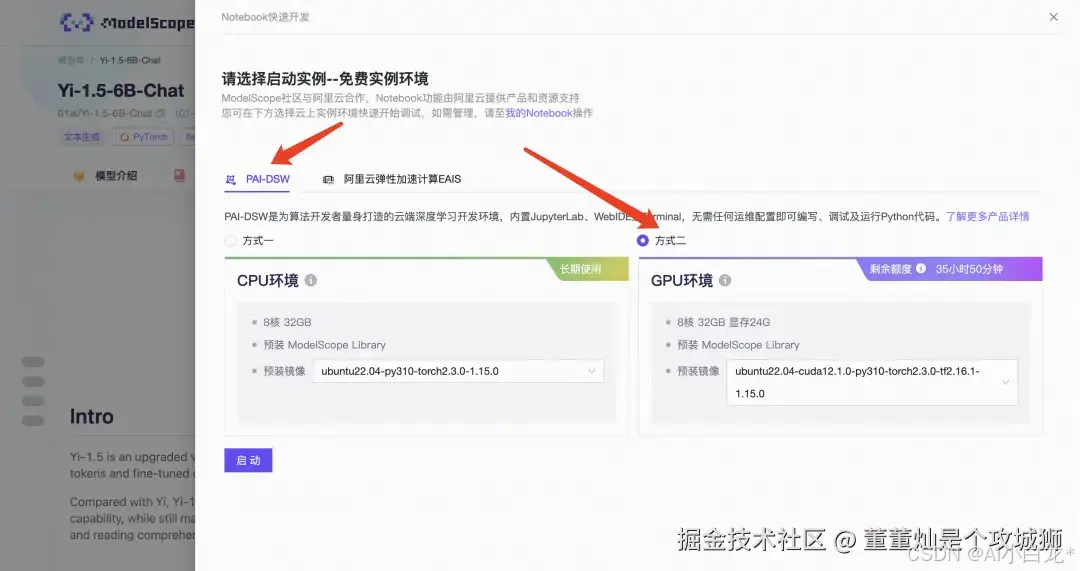
选择完方式二:GPU环境后,点击“启动”。
启动大概需要2分钟,等GPU环境启动好以后点击"查看NoteBook"进入。
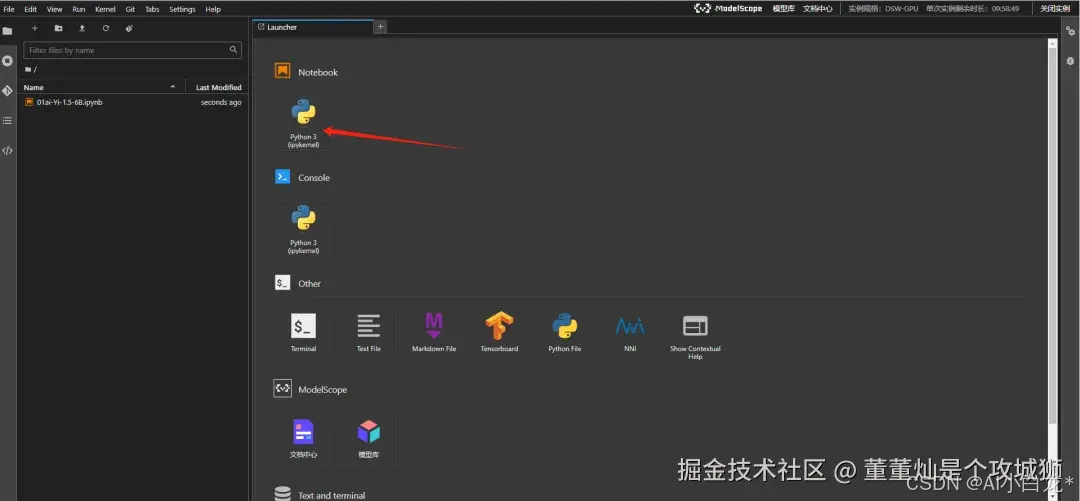
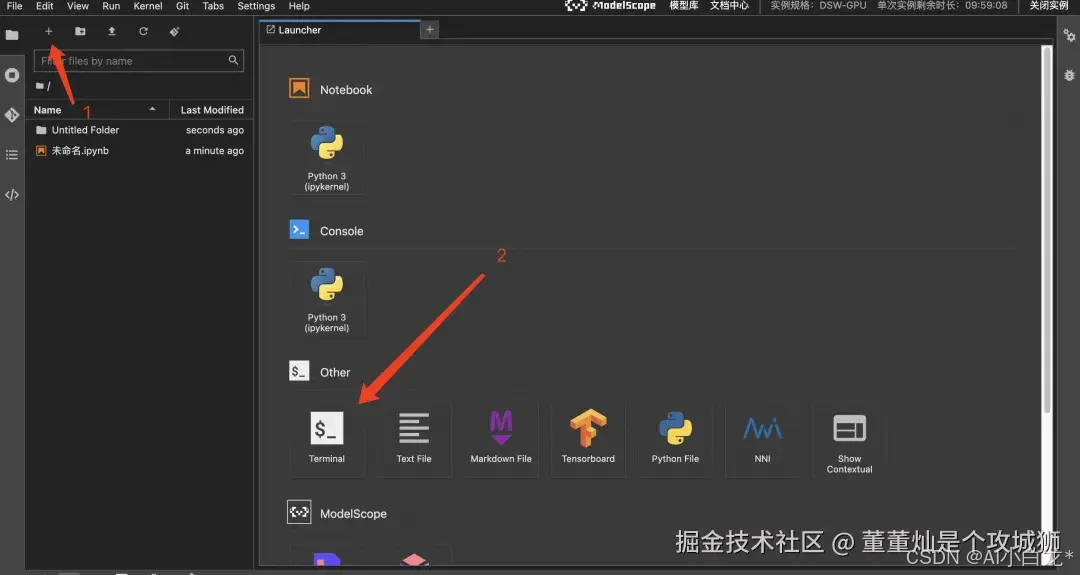
魔塔社区内置了JupyterLab的功能,你进入之后,可以找到 Notebook 标签,新建一个Notebook(当然你在terminal 里执行也没问题)。
如下箭头所示,点击即可创建一个新的 Notebook 页面。
增添一个代码块,并且执行以下命令(点击左侧的运行按钮运行该代码块,下同,这一步是安装依赖库)。
拉取 LLaMA-Factory,过程大约需要几分钟
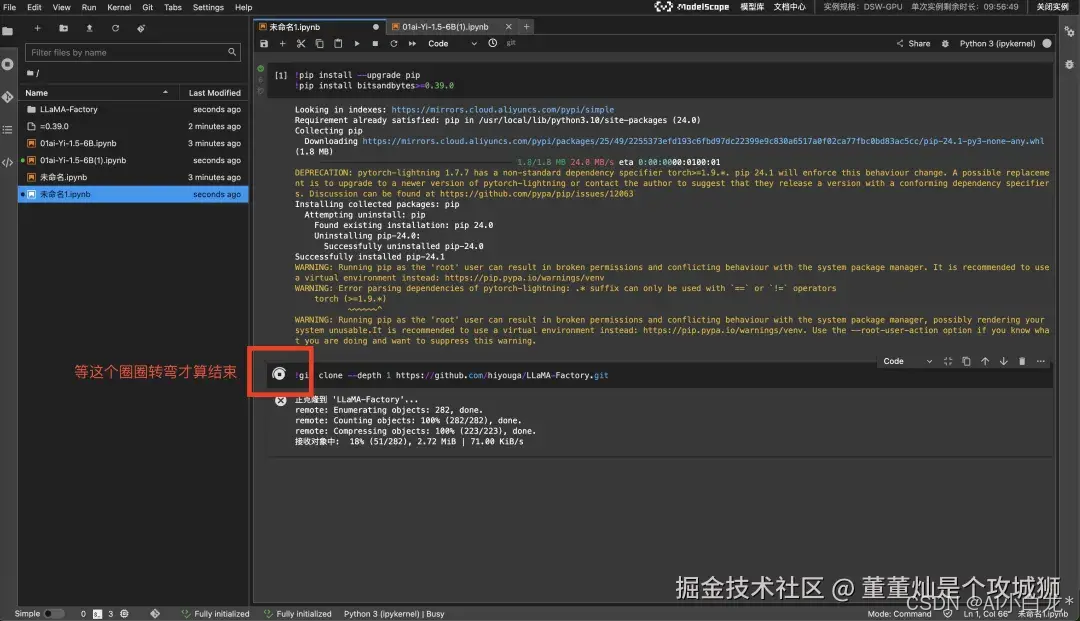
接下来需要去 Launcher > Terminal 执行(按照图片剪头指示操作)。
安装依赖的软件,这步需要的时间比较长。
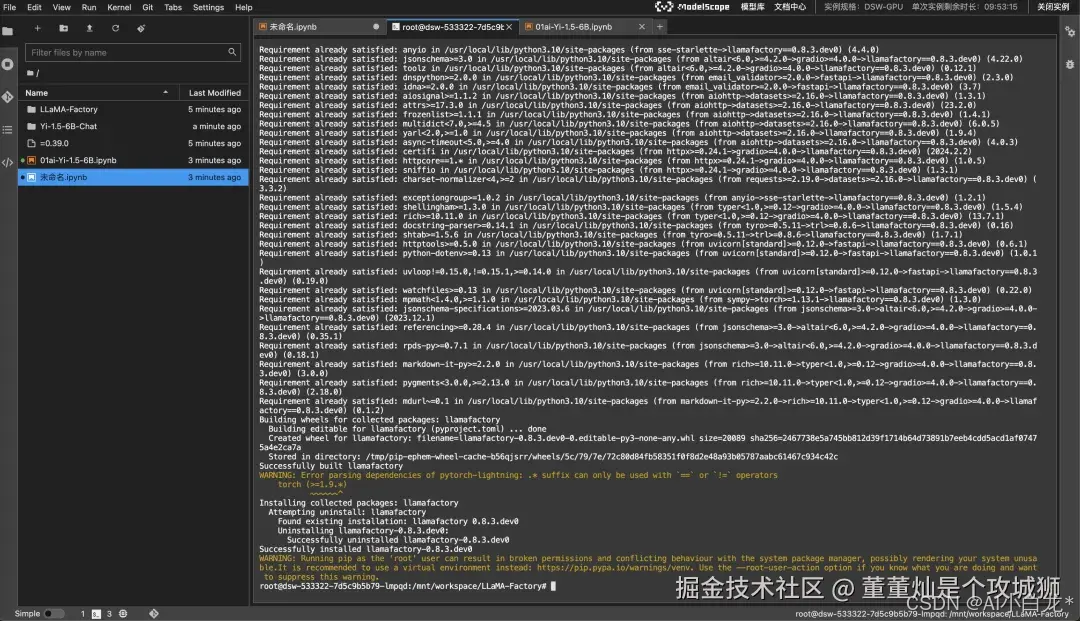
等以上所有步骤完成后,再进行下面的操作。
零一万物的 Yi 开源大语言模型的权重可以在HuggingFace和ModelScope上找到,这里我选择从ModelScope上下载。
零一万物的所有开源模型链接在这里:
www.modelscope.cn/organizatio…
模型下载需要一定的时间,这里选择了最小的Yi-1.5-6B-chat模型进行实验。
模型的说明在这里:
www.modelscope.cn/models/01ai…
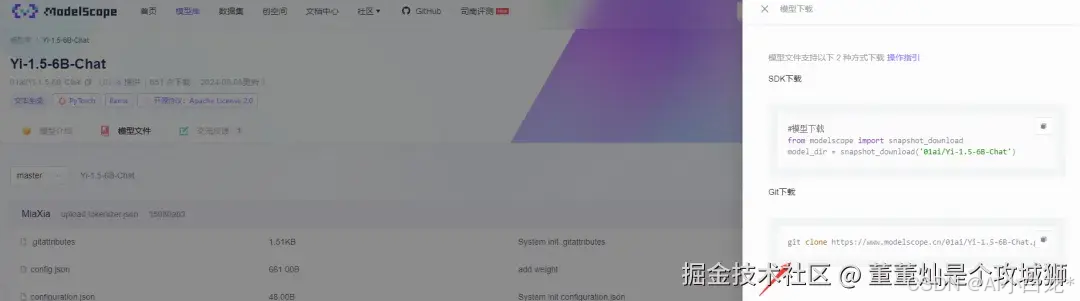
Yi-1.5-6B-chat模型大小大约12G,下载大约需要10分钟(取决于网速)。
接下来,你通过下面的命令就可以在 notebook 里执行下载(在 terminal也一样,如果需要在terminal执行需要去掉前面的!)。
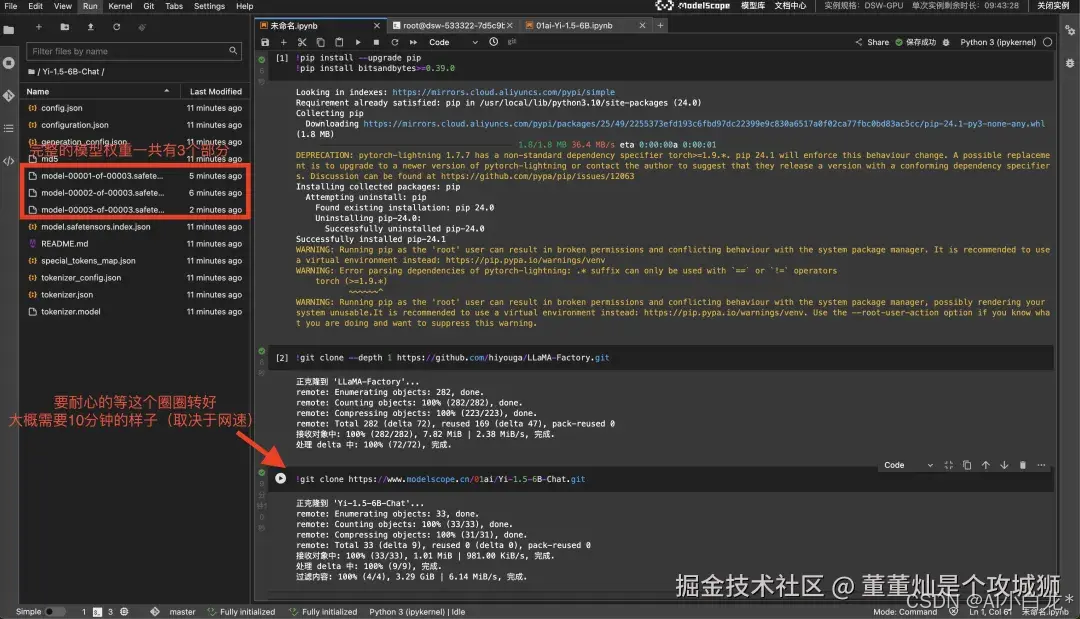
这一步,耐心等待下载完成即可。
等以上所有步骤完成后,准备工作就做好了,现在可以开始准备微调了。
⚠️注意:虽然本篇文章仅仅是简单的过一遍微调的流程,但是不要低估他的难度。微调跑起来很容易,但是跑出很好的结果非常的难。
开源社区有许多非常优秀的专门用于微调代码库具体的你可以参考这里:
github.com/01-ai/Yi-1.…
站在巨人的肩膀上开始这次实战,这里选择llama_factory。
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术。llama_factory 的介绍可以在这里查看:
github.com/hiyouga/LLa…
a. 创建微调训练相关的配置文件
在左侧的文件列表,Llama-Factory的文件夹里,打开examples rain_qlora(注意不是 train_lora)下提供的llama3_lora_sft_awq.yaml,一份并重命名为yi_lora_sft_bitsandbytes.yaml。
这个文件里面写着和微调相关的关键参数。
打开这个文件,将第一行model_name_or_path更改为你下载模型的位置。
同样修改其他行的内容,下面是我的修改,你可以逐行对比一下,有不一致或缺少的就添加一下。
从上面的配置文件中可以看到,本次微调的数据集是 identity。
那这个文件里面写着什么呢?
你可以打开这个文件看一下:github.com/hiyouga/LLa…

微调数据集是“自我认知”,也就是说当你问模型“你好你是谁”的时候,模型会告诉你我叫name由author开发。
如果你把数据集更改成你自己的名字,那你就可以微调一个属于你自己的大模型。
这一步,你可以将 identity.json 中的 {{name}} 字段替换为你的名字来微调一个属于自己的大模型。
保存刚才对于 yi_lora_sft_bitsandbytes.yaml 文件的更改,回到终端terminal。
在 LLaMA-Factory 目录下,输入以下命令启动微调脚本(大概需要10分钟)
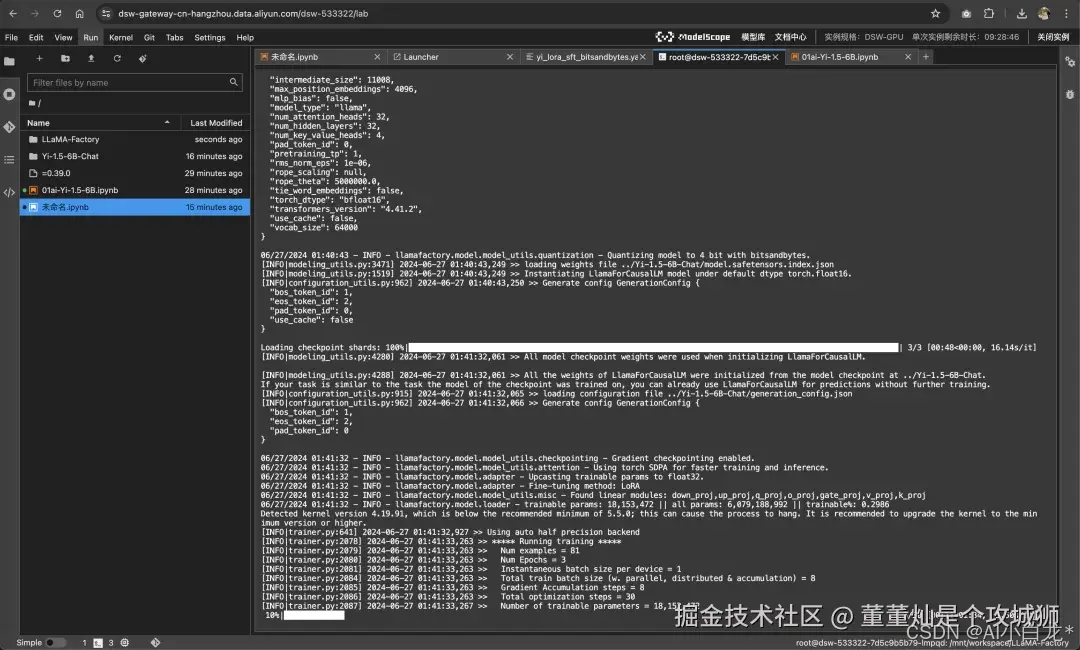
看到进度条就是开始微调了。
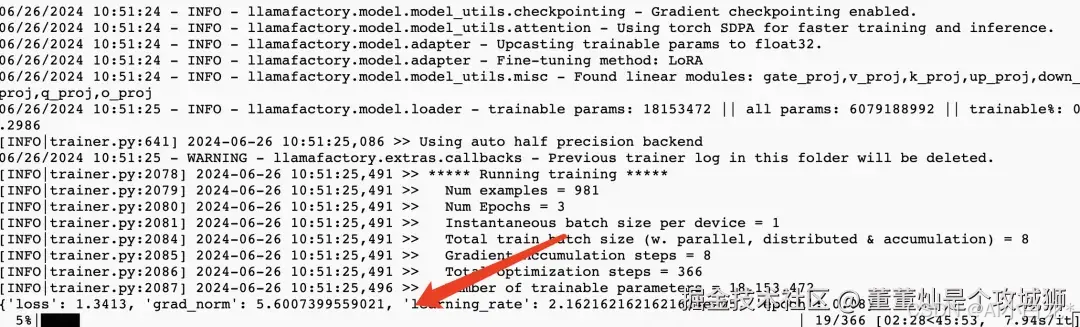
运行过程大概需要10分钟,当你看到下面这个界面的时候,微调过程就结束了。
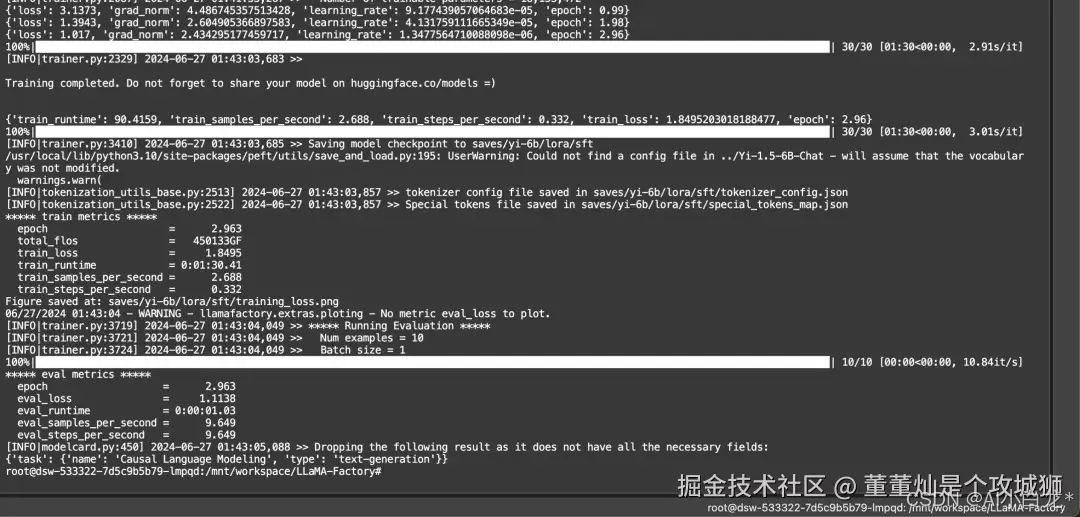
6. 推理测试
微调后的模型有什么不同的地方呢?
这里加载微调后模型进行推理,测试微调前后变化。
参考Llama-Factory文件夹中,examplesinference下提供的llama3_lora_sft.yaml,一份,并重命名为 yi_lora_sft.yaml
将内容更改为,并且保存(一定记得保存)****。
回到刚刚结束微调的终端Terminal,运行下面的推理命令(同样在Llama-Factory目录下运行)。
稍微等待一下模型加载,然后就可以聊天了。
可以看到模型的自我身份认知被成功的更改了。
自我身份认知更改成为数据集规定的样子了,同时也保持了通用对话能力。
那么,和没有经过微调之前的模型对比有什么差别呢?
重复上面的步骤,将llama3.yaml并重命名为yi.yaml,将内容更改为以下的内容,并保存(一定记得保存)。
回到终端Terminal,运行下面的推理命令:
可以提问和刚才同样的问题,看到模型的原始回答。

基于本实验,你就完成了一个简单的微调,完整的走了一遍模型的微调过程,是不是还挺简单的?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “?”“”等问题热议不断。
事实上,
继等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 分享出来:包括等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)👈

AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)


四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 包括等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)👈
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:975644476@qq.com
本文链接:http://www.gawce.com/tnews/6586.html







最新文章
-

台式怎么连接手机热点(台式怎么连接手机热点共享网络的)
2025-12-15 -
华为手机u设置(华为手机u设置在哪)
2025-12-15 -

华为手机官网报价(华为手机官网报价大全表)
2025-12-15 -

手机号银行卡(手机号银行卡解绑)
2025-12-15 -

手机号变成空号(手机号变成空号了充话费还能用么)
2025-12-15 -

tcl手机游戏(tcl手机自带游戏)
2025-12-15 -

手机个人资料(手机个人资料被换成别人的怎么办)
2025-12-15 -

手机 在线 视频(手机在线视频转换工具)
2025-12-15
热门文章
-

手机网站你懂得(来个手机能看的网站2021你懂的)
2025-01-18 -

在线识图找图_在线识图
2024-12-06 -

如何通过数字人民币提现到银行卡?详细步骤和注意事项
2024-12-25 -

oppo手机没声音怎么办(oppo手机如果没有声音怎么办)
2025-02-16 -

微信群不是群主怎么艾特所有人
2024-12-16 -

红米k70怎么设置门禁卡nfc
2024-12-27 -

水饺皇后:从街头小摊做起,将一碗水饺做到年销60亿
2025-03-05 -

400106(信威集团)的重组已经成功。信威集团在2024年完成了与天骄的重组,
2024-12-08