中国AI实力升级人工智能大模型体验报告2.0揭示讯飞星火领先地位


8月12日,新华社发布了一份重要的报告——《人工智能大模型体验报告2.0》。这份报告对当下多款热门国产大模型进行了全面而深入的横向测评,包括讯飞星火、百度文心一言、商汤商量、阿里通义千问、智谱 AI-ChatGLM、昆仑万维天工、澜舟 Mchat以及360 智脑。经过一系列严格的测试和评估,讯飞星火以其卓越的表现赢得了总分第一的荣誉,成为了现阶段国产大模型的“领头羊”。这一结果无疑证明了讯飞星火在人工智能领域的领先地位,也再次突显了中国在大模型研发和应用方面的强大实力。
报告将大模型的能力拆解为四个维度:基础能力指数、智商指数、情商指数以及工具提效指数。这四个维度全面覆盖了大模型的各个重要方面,为我们提供了更加深入、全面的了解。
值得一提的是,这次的报告不仅由研究院研究员进行深度体验,还特别邀请了北京大学文化与传播研究所的专家学者,以及其他业界、学界的专家参与。他们的专业知识和丰富经验为报告的编写提供了强大的支持。
报告还增设了500道测评题目,对各款大模型的优劣特长进行了全面、客观的综合性评估。这种多元化的评估方式,使得我们能够从更多角度去理解和评价大模型的性能。
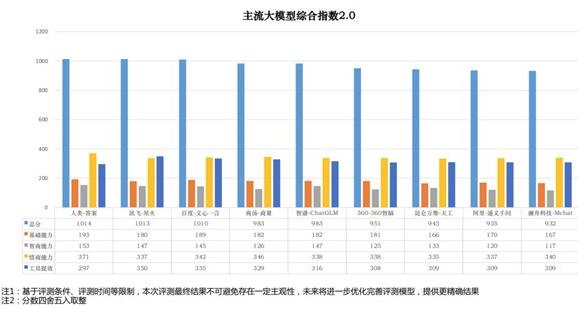
大模型,作为数智化社会的基石,其技术源头追溯具有深远的意义。在基础能力方面,课题组从语言能力、AI 向善、跨模态和多轮对话四大指标对大模型进行了测评。结果显示,讯飞星火、商汤商量、文心一言等五款大模型在180分的高分红线之上脱颖而出。尽管总体而言,人类与 AI 之间的差距并不显著,但各家大模型的持续性投入使得这一差距逐渐缩小。
在智商评估中,课题组从常识知识、逻辑能力和专业知识等方面对大模型进行了深入考察。结果发现,讯飞星火与智谱 AI-ChatGLM 以147分并列第一。这意味着它们在处理复杂问题时能够提供更严谨的思维逻辑和更强大的分析决策能力,从而推动人工智能从认知走向感知。结合医疗、法律等专业领域的推理能力,这些大模型有助于在特定领域中进行更准确与高效的问题处理。
在大模型能否帮助人类工作提质增效这一问题上,报告给出了积极的反馈。报告显示,讯飞星火提供了丰富、有效的工具,包括代码生成、数据自动分析和可视化工具、文件整理等,这些工具足以帮助人类更快、更从容地完成工作任务。同时,讯飞星火还能提供新的思路和方法,推动业务流程、选题创新和内容创新等工作方式的改进和升级。在这一评估中,讯飞星火以350分的大比分领先于其他大模型,与第二名拉开了15分的巨大差距。
值得一提的是,科大讯飞还于8月15日举行了星火 V2.0 升级发布会,带来代码能力的突破。更重要的是,他们将进一步完善私有化代码能力平台,使大模型在重点领域和关键环节实现全栈式自主可控。这将为客户提供业界领先的技术支持,推动人工智能技术的进一步发展和应用。
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:975644476@qq.com
本文链接:http://www.gawce.com/tnews/6546.html






最新文章
-

台式怎么连接手机热点(台式怎么连接手机热点共享网络的)
2025-12-15 -
华为手机u设置(华为手机u设置在哪)
2025-12-15 -

华为手机官网报价(华为手机官网报价大全表)
2025-12-15 -

手机号银行卡(手机号银行卡解绑)
2025-12-15 -

手机号变成空号(手机号变成空号了充话费还能用么)
2025-12-15 -

tcl手机游戏(tcl手机自带游戏)
2025-12-15 -

手机个人资料(手机个人资料被换成别人的怎么办)
2025-12-15 -

手机 在线 视频(手机在线视频转换工具)
2025-12-15
热门文章
-

手机网站你懂得(来个手机能看的网站2021你懂的)
2025-01-18 -

在线识图找图_在线识图
2024-12-06 -

如何通过数字人民币提现到银行卡?详细步骤和注意事项
2024-12-25 -

oppo手机没声音怎么办(oppo手机如果没有声音怎么办)
2025-02-16 -

微信群不是群主怎么艾特所有人
2024-12-16 -

红米k70怎么设置门禁卡nfc
2024-12-27 -

水饺皇后:从街头小摊做起,将一碗水饺做到年销60亿
2025-03-05 -

400106(信威集团)的重组已经成功。信威集团在2024年完成了与天骄的重组,
2024-12-08